Java 的 CMS 垃圾回收器和 G1 垃圾回收器在记忆集的维护上有什么不同?
Java 的 CMS 垃圾回收器和 G1 垃圾回收器在记忆集的维护上有什么不同?
回答重点
CMS 垃圾回收器:
- CMS 使用卡表(Card Table,记忆集的一种实现) 来记录老年代中引用新生代的对象。卡表的维护较为简单,老年代对象指向新生代对象时,会触发写屏障并标记相应的卡片。
- CMS 的卡表是通过写屏障维护的,当老年代对象引用新生代对象时,CMS 会在卡表中将对应区域标记为“脏卡”,以便在 GC 时扫描这些区域。
G1 垃圾回收器:
- G1 的记忆集(Remembered Set),其粒度可以细化到堆的各个区域(Region)。记忆集用于跟踪一个 Region 中的对象引用了其他 Region 的对象。
- G1 采用多层次的记忆集维护机制,将老年代对新生代的引用、其他 Region 之间的引用关系都记录在记忆集中。每个 Region 都有自己的记忆集,维护成本相对较高,但有助于 G1 进行精准的增量式回收。
- 精确度:G1 的记忆集在某些情况下会比 CMS 的卡表更加精细和准确,可以根据需要选择扫描的具体区域,而 CMS 的卡表往往只能标记大范围的区域。
扩展知识
points-out 和 points-into
cms 的记忆集的实现是卡表即 card table。
通常实现的记忆集是 points-out 的,我们知道记忆集是用来记录非收集区域指向收集区域的跨代引用,它的主语其实是非收集区域,所以是 points-out 的。
在 cms 中只有老年代指向年轻代的卡表,用于年轻代 gc。
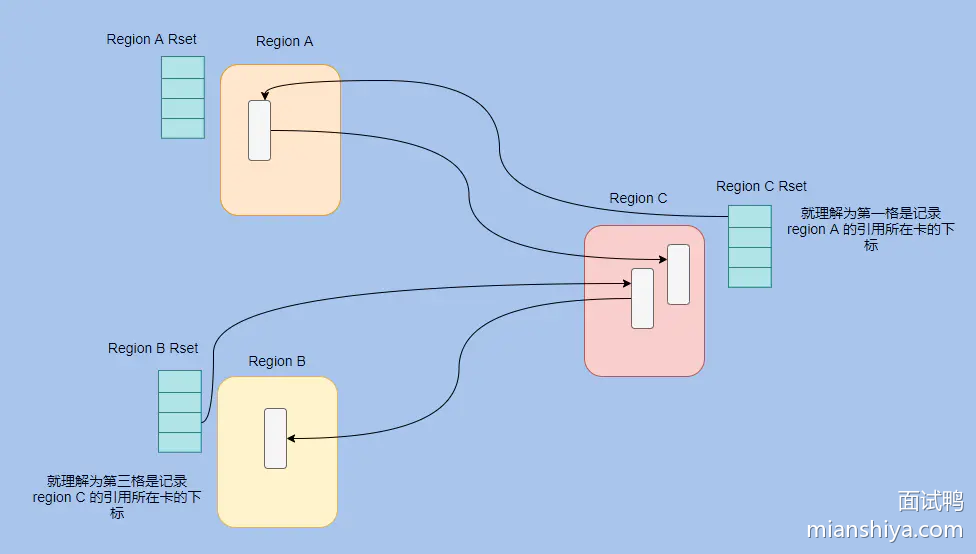
而 G1 是基于 region 的,所以在 points-out 的卡表之上还加了个 points-into 的结构。
因为一个 region 需要知道有哪些别的 region 有指向自己的指针,然后还需要知道这些指针在哪些 card 中。
其实 G1 的记忆集就是个 hash table,key 就是别的 region 的起始地址,然后 value 是一个集合,里面存储这 card table 的 index。
我们来看下这个图就很清晰了。
像每次引用字段的赋值都需要维护记忆集开销很大,所以 G1 的实现利用了 logging write barrier。
也是异步思想,会先将修改记录到队列中,当队列超过一定阈值由后台线程取出遍历来更新记忆集。
logging write barrier
Comments